- Update config.json (b1f5635c466812741bf0b50137f5f79ce0fd6d36) Co-authored-by: Yih-Dar SHIEH <ydshieh@users.noreply.huggingface.co> |
||
|---|---|---|
| .gitattributes | ||
| README.md | ||
| config.json | ||
| generation_config.json | ||
| merges.txt | ||
| preprocessor_config.json | ||
| pytorch_model.bin | ||
| special_tokens_map.json | ||
| tokenizer_config.json | ||
| vocab.json | ||
README.md
| tags | widget | ||
|---|---|---|---|
|
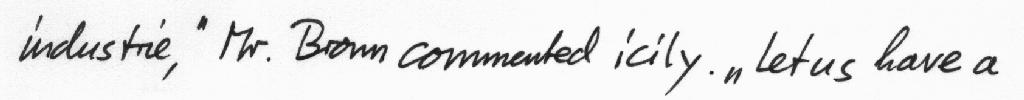{kind=link}
TrOCR (base-sized model, fine-tuned on IAM)
TrOCR model fine-tuned on the IAM dataset. It was introduced in the paper TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models by Li et al. and first released in this repository.
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the model hub to look for fine-tuned versions on a task that interests you.
How to use
Here is how to use this model in PyTorch:
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-handwritten')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
BibTeX entry and citation info
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}